Ollama 是在自己的机器上本地运行大型语言模型 (LLM) 的最简单方法之一。
它类似于 Docker。用户可以使用 Hugging Face 的命令行界面下载公开可用的模型。将 Ollama 与图形界面连接,便拥有了一个可替代 ChatGPT 的本地 AI 工具。
在本指南中,我们将了解一些基本的 Ollama 命令,解释它们的作用,并在最后分享一些技巧来提升使用体验。
1] 检查可用命令
在深入研究特定命令之前,让我们先从基础知识开始。要查看所有可用的 Ollama 命令,则运行如下命令:
# ollama --help
这条命令将列出所有可能的命令以及它们功能的简要说明。如果需要特定命令的详细信息,可以使用:
# ollama--help
例如,”ollama run –help”将显示运行模型的所有可用选项。
以下是一些基本的 Ollama 命令,我们将在文章中更详细地介绍它们:
| 命令 | 描述 |
|---|---|
| ollama create | 从模型文件创建自定义模型,允许微调或修改现有模型 |
| ollama run <model> | 运行指定的模型来处理输入文本、生成响应或执行各种 AI 任务 |
| ollama pull <model> | 从 Ollama 的库下载模型以在本地使用 |
| ollama list | 显示系统上安装的所有模型 |
| ollama rm <model> | 从系统中删除特定模型以释放空间 |
| ollama serve | 将 Ollama 模型作为本地 API 端点运行,有助于与其他应用程序集成 |
| ollama ps | 显示当前正在运行的 Ollama 进程 |
| ollama stop <model> | 使用进程 ID 或名称停止正在运行的 Ollama 进程 |
| ollama show <model> | 显示特定模型的元数据和详细信息,包括其参数 |
| ollama run <model> “with input” | 使用特定的文本输入执行模型,例如生成内容或提取信息 |
| ollama run <model> “with file input” | 使用 AI 模型处理文件(文本、代码或图像)以提取见解或执行分析 |
1. 下载一个 LLM
如果想从 Ollama 库手动下载模型而不立即运行它,则使用:
# ollama pull <model_name>
例如,要下载 Llama 3.2(300M 参数):
# ollama pull phi:2.7b

图.1 ollama 下载 LLM 命令
命令执行完成后,会将模型存储在本地,使其可供离线使用。
需要注意的是:Hugging Face 无法获取可用的模型名称,所以我们必须访问 Ollama 网站并获取可用的模型名称,然后使用 pull 命令进行操作。
2. 运行一个 LLM
要运行一个模型,以进行与模型聊天的操作,则可以执行如下命令:
# ollama run <model_name>
例如,要运行 Pi2 这样的小模型,则执行:
# ollama run phi:2.7b
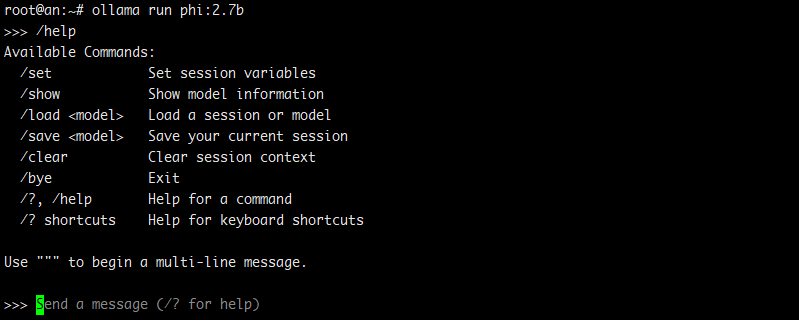
图.2 使用 ollama 命令本地运行 LLM
如果尚未下载要运行的模型,Ollama 将自动获取。模型运行后,就可以直接在终端中与其进行交互。
与正在运行的模型交互时的一些实用技巧:
- 输入 /set parameter num_ctx 8192 可调整上下文窗口
- 使用 /show info 可显示模型详细信息
- 输入 /bye 可退出
3. 列出已安装的 LLM
如果我们下载了多个模型,可能需要查看哪些模型在本地可用。就可以使用以下命令执行此操作:
# ollama list
可能的输出结果如下:

图.3 ollama 列出所有已安装 LLM
4. 查看运行 LLM 信息
如果运行多个模型并想查看哪些模型处于活动状态,请使用:
# ollama ps

图.4 查看运行 LLM 信息
要停止正在运行的模型,只需退出其会话或重新启动 Ollama 服务器即可。
5. 启动 ollama 服务器
“ollama serve”命令会启动一个本地服务器来管理和运行 LLM。
如果想通过 API 而不是仅仅使用命令行与模型交互,则此命令必不可少。
# ollama serve
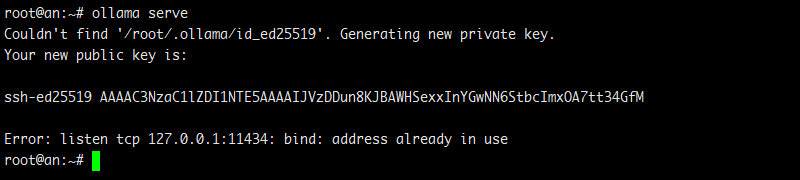
图.5 启动 ollama 服务器
默认情况下,服务器在”http://localhost:11434/”上运行,可以通过浏览器访问该服务器。
我们还可以使用环境变量配置服务器,例如:
- OLLAMA_DEBUG=1 → 启用调试模式以进行故障排除
- OLLAMA_HOST=0.0.0.0:11434 → 将服务器绑定到其他地址/端口
6. 更新现有 LLM
由于没有用于更新现有 LLM 的 ollama 命令,于是我们可以定期运行 pull 命令来更新已安装的模型:
# ollama pull <model_name>
如果要更新所有模型,可以使用如下组合命令:
# ollama list | tail -n +2 | awk '{print $1}' | xargs -I {} ollama pull {}
这就是 AWK 脚本工具的魔力所在,也是 xargs 命令的强大之处。
该命令的工作原理如下:
Ollama 会列出所有模型,由于第 1 行没有模型名称,因此需要从第 2 行开始获取输出。然后,AWK 命令会返回包含模型名称的第一列。现在,该列会传递给 xargs 命令,该命令会将模型名称放入 {} 占位符中,因此,对于每个已安装的模型,ollama pull {} 都会以 ollama pull model_name 的形式运行。
7. 自定义模型配置
Ollama 最酷的功能之一是能够创建自定义模型配置。
例如,假设我们想调整 smollm2 以获得更长的上下文窗口。
首先,在工作目录中创建一个名为 Modelfile 的文件,其内容如下:
FROM llama3.2:3b PARAMETER temperature 0.5 PARAMETER top_p 0.9 SYSTEM You are a senior web developer specializing in JavaScript, front-end frameworks (React, Vue), and back-end technologies (Node.js, Express). Provide well-structured, optimized code with clear explanations and best practices.
现在,就可以使用 Ollama 从 Modelfile 创建一个新模型:
# ollama create js-web-dev -f Modelfile
一旦创建了模型,就可以以交互方式运行它:
# ollama run js-web-dev "Write a well-optimized JavaScript function to fetch data from an API and handle errors properly."
如果想进一步调整模型:
- 调整程序以提高随机性(0.7)或严格准确率(0.3)
- 修改 top_p 以控制多样性(0.8 可实现更严格的响应)
- 添加更具体的系统指令,例如”专注于 React 性能优化”
2] 其他一些提升使用体验的技巧
Ollama 不仅仅是一个本地运行大语言模型的工具,它还可以作为终端内强大的 AI 助手,执行各种任务。
例如,可以使用 Ollama 从文档中提取信息、分析图像,甚至在不离开终端的情况下协助编写代码。
需要提示的是:在没有 GPU 的情况下运行 Ollama 进行图像处理、文档分析或代码生成可能会非常慢。
总结文档
Ollama 可以快速从长篇文档、研究论文和报告中提取关键点,从而免于数小时的手动阅读。
不过,不建议用它来处理 PDF 文件。它的结果可能会很差,尤其是在文档格式复杂或包含扫描文本的情况下。
但是,如果处理的是结构化文本文件,它的效果还是相当不错的:
# ollama run phi "Summarize this document in 100 words." < french_revolution.txt
图像分析
虽然 Ollama 主要处理文本,但一些视觉模型(例如 llava 甚至 deepseek-r1)开始支持多模态处理,这意味着它们可以分析和描述图像。
这在计算机视觉、无障碍访问和内容审核等领域尤为有用:
# ollama run llava:7b "Describe the content of this image." < cat.jpg
代码生成和协助
调试复杂的代码库?需要理解一段不熟悉的代码?
与其花费数小时解读,不如让 Ollama 帮你搞定:
# ollama run phi "Explain this algorithm step-by-step." < algorithm.py
总之,Ollama 让用户能够在自己的硬件上驾驭 AI。虽然一开始可能感觉很复杂,但一旦掌握了基本命令和参数,它就会成为任何开发者工具包中一个非常有用的补充。