太多 Kubernetes 集群因 etcd 部署仓促或配置失误而导致故障。本教程将通过经过验证的命令、简洁规范的配置文件以及详实的验证步骤,手把手演示如何搭建一个生产级的三节点 etcd 集群。学习本教程有助于避开常见陷阱,在遭遇停机或数据不一致问题之前,为生产环境构建起一道稳固可靠的基石。
如果系统运行的 Kubernetes 环境规模已超出”玩具级”范畴,那么控制平面其可靠性将完全取决于其底层数据存储的可靠性。而这一数据存储正是 etcd。务必将其视为核心的重要组件,而非可有可无的附属品。
单节点 etcd 确实能用–但这种可用性终有失效之时。一旦开始关注系统的正常运行时间、数据一致性以及故障恢复能力,就必须采用集群化部署方案。在本教程中,我们将学习如何以正确的方式构建一个 3 节点的 etcd 集群:确保其具备可预测性、容错能力,并达到生产级应用标准。
1] 什么是 etcd
etcd 是一个基于 Raft 共识算法的分布式强一致性键值存储系统。它的设计目标是可靠性,而非极致速度(etcd 官方网站)。
核心特性:
- 强一致性(CP 系统):避免读取过期数据
- 分布式设计:数据在节点间复制
- 基于领导者(leader)的写入:一个领导者,多个跟随者
- 简洁的 API(gRPC/HTTP):易于集成和自动化
所以,可以将 etcd 视为集群状态的权威来源。如果 etcd 宕机或损坏,控制平面将无法获取集群状态信息。
etcd 在 Kubernetes 中的作用
在 Kubernetes 中,etcd 是所有重要数据的后端数据库。
etcd 存储的内容:
- 集群状态(节点、Pod、Service)
- 配置(ConfigMap、Secret)
- 调度数据
- Leader 选举元数据
它的运作方式:
- kube-apiserver → etcd(读写所有状态)
- 控制器和调度器通过 API 服务器间接交互
- 没有 etcd = 没有集群状态 = 无法做出调度决策
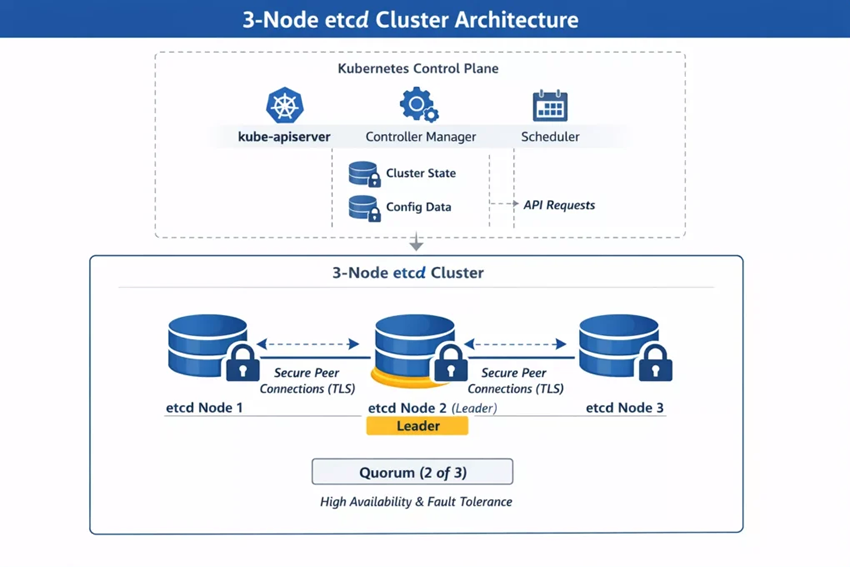
图.1 3 etcd 节点集群架构
归根结底:etcd 并非”Kubernetes 的一部分”–它是 Kubernetes 的基石。
etcd 集群配置 3 节点的原因
将 etcd 部署为集群是为了提高生存能力,而非扩展性。
为什么选择 3 个节点:
- 基于仲裁的共识–需要多数节点(2/3 个节点)
- 容错性–即使丢失一个节点也能保持运行
- 避免脑裂–Raft 机制强制使用单个领导者
优势:
- 控制平面状态的高可用性
- 更安全的升级和维护窗口
- 更强的节点或网络故障恢复能力
劣势:
- 单点故障(单节点配置)
- 故障期间写入功能不可用
- 手动恢复的风险
何时真正需配置 3 节点,切勿过度设计,但也绝不可偷工减料。
在以下情况下,请使用 3 节点 etcd 集群:
- 正在运行多节点 Kubernetes 集群
- 需要生产级的高可用性(正常运行时间)
- 高度重视数据一致性与可恢复性
仅在以下情况下,才可省略集群化配置:
- 身处实验室环境、开发测试机,或是一次性的临时环境
完成本教程后,我们将拥有:
- 一个采用静态对等节点配置的 3 节点 etcd 集群
- 安全的通信机制(若遵循最佳实践,将启用 TLS 加密)
- 已通过验证的集群健康状态与法定多数(Quorum)状态
- 一个随时可为 Kubernetes 控制平面提供支撑的配置环境
这些内容,绝无空洞的泛泛之谈。最终将获得一个简洁、可靠且功能正常的集群。
2] 系统配置条件
etcd 是 Kubernetes 等分布式系统的基石。如果配置错误,控制平面将无法正常运行。本教程将使用 systemd 和 TLS(可选,但强烈建议使用)搭建一个干净、可复现的三节点 etcd 集群。
节点基础设施要求:
- 3 个 Linux 节点(Rocky Linux / Ubuntu / Debian)
- 静态 IP 地址和主机名
例如:
node1: 172.16.100.1 node2: 172.16.100.2 node3: 172.16.100.3
设置主机名:
sudo hostnamectl set-hostname node1 sudo hostnamectl set-hostname node2 sudo hostnamectl set-hostname node3
在所有节点的”/etc/hosts”文件中增加如下内容:
172.16.100.1 node1 172.16.100.2 node2 172.16.100.3 node3
系统要求:
软件防火墙放行端口:
- 2379(客户端)
- 2380(同伴)
启用系统时钟同步(chrony/ntpd 均可):
/* 基于 Debian 的发行版 */ sudo apt install -y chrony sudo systemctl enable --now chrony /* 基于 RHEL 的发行版 */ sudo dnf install -y chrony sudo systemctl enable --now chronyd
另外,为了提升 Kubernetes etcd 集群的可靠性,建议使用高性能 NVMe SSD 以实现最佳磁盘 I/O 性能。etcd 的写入密集型操作需要快速存储来最大限度地降低延迟并确保集群稳定性。
3] 部署和配置 etcd 集群
第一步:安装 etcd
所有节点均下载最新版的 etcd 可执行文件,解压后将其到系统可执行目录:
# wget https://github.com/etcd-io/etcd/releases/download/v3.6.10/etcd-v3.6.10-linux-amd64.tar.gz # tar -zxvf etcd-v3.6.10-linux-amd64.tar.gz # mv etcd-v3.6.10-linux-amd64/etcd etcd-v3.6.10-linux-amd64/etcdctl /usr/local/bin/ # chmod +x /usr/local/bin/etcd* # etcd --version # etcdctl version
如果执行最后两条命令,出现如下显示,则表示 etcd 程序已经安装完成:

图.2 验证 etcd 程序安装状态
第二步:创建数据目录
所有节点均执行如下命令,以创建数据目录:
# mkdir -p /var/lib/etcd # chown -R $(whoami):$(whoami) /var/lib/etcd
第三步:定义集群配置
我们将使用静态集群引导程序,所有节点均执行如下配置命令:
# ETCD_INITIAL_CLUSTER="node1=http://172.16.100.1:2380,node2=http://172.16.100.2:2380,node3=http://172.16.100.3:2380"
第四步:创建系统服务
在 node1 节点执行如下命令,以创建系统服务:
# tee /etc/systemd/system/etcd.service <
对于 node2 和 node3 节点,分别修改以上命令的 Ip 地址和主机名,同样创建系统服务,修改内容如下:
对于 node2 节点 --name node2 \\ --data-dir /var/lib/etcd \\ --initial-advertise-peer-urls http://172.16.100.2:2380 \\ --listen-peer-urls http://172.16.100.2:2380 \\ --listen-client-urls http://172.16.100.2:2379,http://127.0.0.1:2379 \\ --advertise-client-urls http://172.16.100.2:2379 \\ 对于 node3 节点 --name node3 \\ --data-dir /var/lib/etcd \\ --initial-advertise-peer-urls http://172.16.100.3:2380 \\ --listen-peer-urls http://172.16.100.3:2380 \\ --listen-client-urls http://172.16.100.3:2379,http://127.0.0.1:2379 \\ --advertise-client-urls http://172.16.100.3:2379 \\
第五步:启动 etcd 集群
所有节点如用如下命令启动集群:
# systemctl daemon-reexec # systemctl daemon-reload # systemctl enable etcd # systemctl start etcd
最后,使用如如下命令查看 etcd 的状态:
# systemctl status etcd
图.3 查看 etcd 集群节点状态
第六步:验证集群状态
设置环境变量:
# export ETCDCTL_API=3
查看集群成员:
# etcdctl --endpoints=http://172.16.100.1:2379,http://172.16.100.2:2379,http://172.16.100.3:2379 member list

图.4 查看集群成员状态
如图.4 所示,如果所有集群成员的状态均是”started”状态,则表示 etcd 集群启动成功了。
验证集群节点健康状态使用如下命令:
# etcdctl --endpoints=http://172.16.100.1:2379,http://172.16.100.2:2379,http://172.16.100.3:2379 endpoint health
查看集群的 leader 使用如下命令:
# etcdctl --endpoints=http://172.16.100.1:2379 endpoint status --write-out=fields # etcdctl --endpoints=http://172.16.100.2:2379 endpoint status --write-out=fields
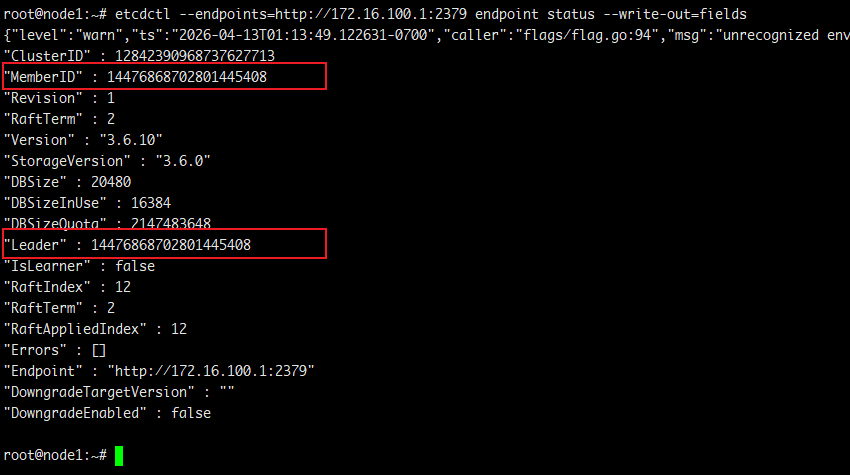
图.5 etcd 集群 leader 节点
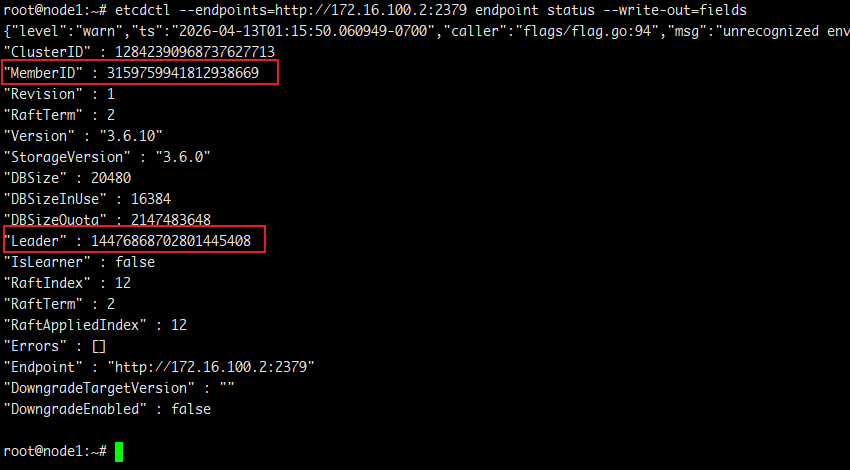
图.6 etcd 集群 flower 节点
第七步:测试集群读写
使用如下命令对集群 leader 节点进行写操作:
# etcdctl --endpoints=http://172.16.100.1:2379 put testkey "cluster working"
在集群的其他节点执行如下命令,以验证集群全局可读:
# etcdctl --endpoints=http://172.16.100.1:2379 get testkey

图.7 验证 etcd 集群全局读写
集群各节点间的数据一致,说明复制功能正常。
可选配置–启用 TLS(生产环境推荐使用)
首先使用如下命令生成一个密钥对:
# openssl genrsa -out ca.key 2048 # openssl req -x509 -new -nodes -key ca.key -subj "/CN=etcd-ca" -days 3650 -out ca.crt
然后使用该密钥生成服务器证书:
# openssl genrsa -out server.key 2048 # openssl req -new -key server.key -subj "/CN=node1" -out server.csr # openssl x509 -req -in server.csr -CA ca.crt -CAkey ca.key -CAcreateserial \ -out server.crt -days 3650 -extensions v3_req \ -extfile <(printf "[v3_req]\nsubjectAltName=IP:172.16.100.1,DNS:node1")
最后,将所有证书文件复制到”/etc/etcd”目录,并更新etcd 服务文件,增加如下内容:
--cert-file=/etc/etcd/server.crt --key-file=/etc/etcd/server.key --client-cert-auth --trusted-ca-file=/etc/etcd/ca.crt --peer-cert-file=/etc/etcd/server.crt --peer-key-file=/etc/etcd/server.key --peer-client-cert-auth --peer-trusted-ca-file=/etc/etcd/ca.crt
一个由 3 个节点组成的 etcd 集群构建可靠控制平面数据存储的最小可行方案。它能提供仲裁、容错能力以及故障时的可预测行为,而无需增加不必要的复杂性。