如果 您一直在关注大型语言模型(LLM)的文章或深入研究 AI,那么您可能不止一次遇到过 token(语义标记)这个术语。但”token”到底是什么?为什么每个人都在谈论它?
它是那些经常被提及的流行语之一,但很少有人以一种可以理解的方式来解释它。
问题就在这里,如果不牢牢掌握 token 是什么,就可能会错过这些模型如何运作的关键部分。
事实上,token 是 LLM 处理和生成文本的核心。如果想知道为什么 AI 似乎对某些单词或短语感到困惑,那么 token 化通常是罪魁祸首。
所以,让我们打破术语,探索为什么 token 对 LLM 的运作如此重要。
什么是 token
token 大型语言模型中读取和理解的一段特殊文本。
它可以短至单个字母,也可以长至单词或单词的一部分。可以将其视为 AI 模型用来处理信息的基本语言单位。
它不是一次性读取整个句子,而是将它们分解成这些碎片化的小片段—— token。
简单来说:
想象一下,假如我们正在尝试教孩子一门新语言,我产都会从基础开始:字母、单词和简单句子。
大语言模型的工作方式也类似,它们将文本分解为更小、更易于管理的单元,也就是 token。
PS:使用 Tiktokenizer 这个方便的工具,就可以可视化和理解不同模型如何对文本进行标记。
例如,句子”敏捷的棕色狐狸跳过了懒狗”可以标记如下:
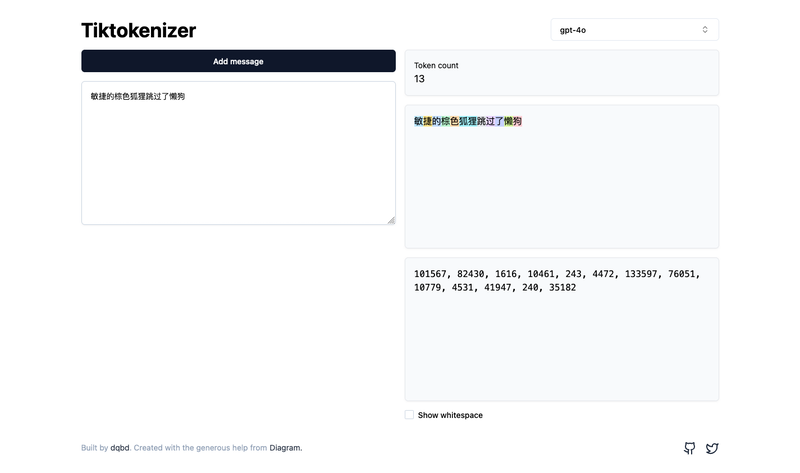
图.1 Tiktokenizer 语义单元示例
大语言模型如何使用标记
一旦文本被标记化,大语言模型就可以分析每个标记以了解其含义和上下文。这使模型能够:
- 理解含义:模型可以识别标记之间的模式和关系,帮助它理解文本的整体含义
- 生成文本:通过分析标记及其关系,模型可以生成新文本,例如完成一个句子、写一个段落,甚至撰写整篇文章
标记化方法
当我们在大型语言模型 (LLM) 的背景下讨论标记化时,重要的是要了解使用不同的方法将文本拆分为标记。让我们来看看目前最常用的方法:
1. 单词级标记化
这是最简单的方法,其中文本用空格和标点符号分隔。每个单词都成为自己的标记。
例如:原始文本是”我喜欢编程。”,则标记为:[“我”、”喜欢”、”编程”、”。”]。虽然这很简单,但效率低下。 例如,”running”和”runner”被视为单独的标记,即使它们共享一个词根。
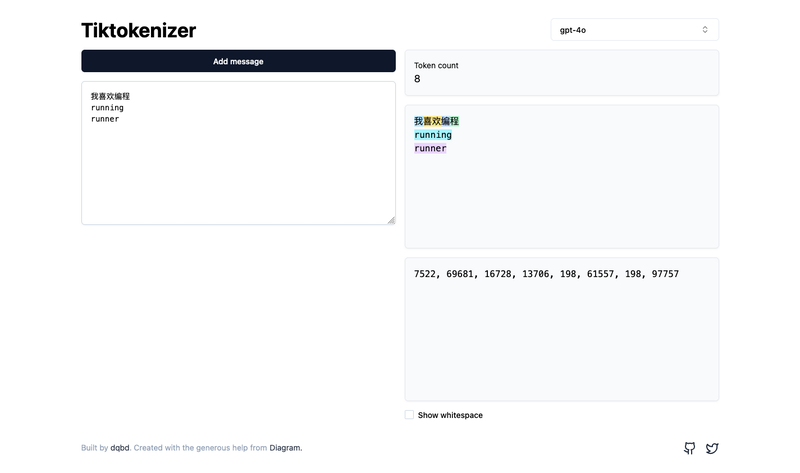
图.2 单词级标记化示例
2. 子词级标记化
子词标记化将单词分解为更小、更有意义的单元,从而提高效率。
它非常适合处理具有常见前缀或后缀的单词,并且可以将罕见或拼写错误的单词拆分为已知的子单词。
两种流行的算法是字节对编码 (BPE) 和 WordPiece。
示例(使用 BPE):原文:”underestimate”,则标记为:[“und”、”erest”、”imate”] 和其他一些标记。
在这种情况下,BPE 将分解为可以在其他词语中使用的更小的单位,从而更容易处理变体和拼写错误。
3. 字符级标记化
此方法将文本拆分为单个字符。
它非常灵活,可以处理任何文本,包括非标准或拼写错误的单词。但是,对于较长的文本,它可能效率较低,因为模型要处理更多的标记。
示例:原始文本:”cat”, 标记成:[“c”、”a”、”t”] 字符级标记化对于极端灵活性很有用,但通常会产生更多标记,这可能需要更繁重的计算。
4. 字节级标记化
字节级标记化将文本拆分为字节,而不是字符或单词。
此方法对于多语言文本和不使用拉丁字母的语言(如中文或阿拉伯语)特别有用。
对于文本的准确表示至关重要的情况,它也很重要。
标记的限制
标记限制是指 LLM 在单个输入中可以处理的最大标记数,包括输入文本和生成的输出。
将其视为缓冲区 – 模型一次可以保存和处理的数据量是有限的。当超过此限制时,模型将停止处理或截断输入。
例如,GPT-3 最多可以处理 4096 个标记,而 GPT-4 最多可以处理 8192 个甚至 32,768 个标记,具体取决于版本。
这意味着交互中的所有内容,从发送的提示到模型的响应,都必须符合该限制。
标记限制的重要性
- 上下文理解:LLM 依赖于先前的令牌来生成上下文准确且连贯的响应,如果模型达到其令牌限制,它将丢失该点以外的上下文,这可能导致输出不太连贯或不完整
- 输入截断:如果您的输入超出令牌限制,模型将切断部分输入,通常从开头或结尾开始。 这可能会导致关键信息的丢失并影响响应的质量
- 输出限制:如果您的输入使用了大部分标记限制,则模型将剩余更少的标记来生成响应。例如,如果您发送一个在 GPT-3 中消耗 3900 个标记的提示,则模型只剩下 196 个标记来提供响应,这可能不足以满足更复杂的查询
标记对于理解 LLM 的运作方式至关重要。
虽然乍一看似乎微不足道,但标记会影响一切,从模型处理语言的效率到其在不同任务和语言中的整体表现。LLM 仍然难以处理非英语语言或代码中的细微差别,而标记化在其中起着重要作用。